概述
工作中看到的问题,写篇笔记记录一下。
一般来说,在表结构中存储树结构只需要添加一个自关联的外键即可(parentId),这种存储结构被被称为邻接表(Adjacency List Model),但邻接表存储树结构在查询方面却存在一定效率问题。
除邻接表之外的另一种存储结构就是预排序遍历树(Modified Preorder Tree Traversal),这种方法通过引入额外的顺序字段维护了树的路径关系,对于树结构较深,或者查询量较大的情况有很大的优势。
邻接表
邻接表是一种最直观的方式,有一定数据结构基础的同学应该对此非常熟悉。
假设我们有如下图需要存储。
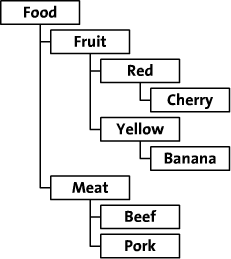
其对应的邻接表为:
| id | parentId |
|---|---|
| Food | |
| Fruit | Food |
| Red | Fruit |
| Cherry | Red |
| Yellow | Fruit |
| Banana | Yellow |
| Meat | Food |
| Beef | Meat |
| Pork | Meat |
表中,每一条记录代表一个节点,parentId表示了当前节点父节点Id,在数据库中,我们可以将parentId和id用外键的方式关联起来。可以看出,邻接表是非常直观的一种方式,该表记录了一颗树的完整信息。
但是当我们需要查询一段路径时,问题就出现了。
比如现在需要查询从Banana到Food的路径,邻接表必须先从Banana开始,找到其父节点Yellow,再上溯到Fruit,最后上溯到Food,才能将整个树的路径查找出来。
在关系型数据库中,这意味着我们需要执行多次SQL查询(即便将多次查询放到自定义函数或者是存储过程中,也无法避免多次查询操作),如果树的层级过深,数据较多,查询效率可能也难以接受。
预排序遍历树
事实上,除了邻接表的结构,一种被称作预排序遍历树的结构可以较好地解决路径查询效率低下的问题。
预排序遍历树本质上还是采用邻接表的方式存储,但该结构通过添加两个用于维护节点关联关系的字段,使得查询路径时可以在一条查询语句内通过直接缩小两个字段的范围来实现。
预排序遍历树的构建过程实际上就是对一棵树进行后序遍历,树的顺序编号从1开始。
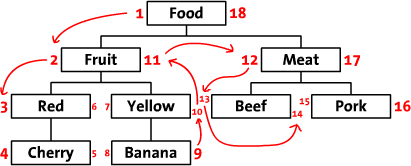
对于每个节点的过程如下:
- 设置当前节点的左序号为flag+1(flag的初始值为0);
- 递归处理左子树;
- 递归处理右子树;
- 设置当前节点的右序号为flag+1。
最终的构建表记录如下:
| id | parentId | left | right |
|---|---|---|---|
| Food | 1 | 18 | |
| Fruit | Food | 2 | 11 |
| Red | Fruit | 3 | 6 |
| Cherry | Red | 4 | 5 |
| Yellow | Fruit | 7 | 10 |
| Banana | Yellow | 8 | 9 |
| Meat | Food | 12 | 17 |
| Beef | Meat | 13 | 14 |
| Pork | Meat | 15 | 16 |
一棵预排序遍历树构建好之后,查询一条路径就简单很多了。
比如还是从Banana到Food,我们可以查找left和right值在Banana和Food之间的所有节点。
1 | select * from tree where left between 1 and 8 and right between 9 and 18; |
查询出的结果如下:
| id | parentId | left | right |
|---|---|---|---|
| Food | 1 | 18 | |
| Fruit | Food | 2 | 11 |
| Yellow | Fruit | 7 | 10 |
| Banana | Yellow | 8 | 9 |
可以看到这种方式查询一条路径时只需要一条语句即可,相比前面的方便很多。
对数据结构比较敏感的同学肯定已经发现,相比最基本的邻接表结构,预排序遍历树对于插入节点的处理要麻烦一些,因为一个节点的插入,对于其他的节点的left和right值会有一定的影响。
当有新节点加入时,我们当然可以从头开始构建这棵树,但这种方式不仅不优雅,而且当数据量比较大时,需要对一整张表的所有记录进行遍历,显然这是无法接受的。
除此之外,我们可以针对性地去处理具体需要变动的节点,假设我们需要插入一个节点,其父节点是Red,id为Strawberry。
我们需要做的具体操作如下:
- 找到我们要插入位置的上一个兄弟节点,假定为preNode;
- 更新比preNode.right大的所有节点的left值,全部+2;
- 更新比preNode.right大的所有节点的right值,全部+2;
- 新增一条记录,left为preNode.right+1,right为preNode.right+2。
SQL语句为:
1 | UPDATE tree SET right=right+2 WHERE right>5; |
这样,一个新的节点就插入了,实际操作起来并不比邻接表麻烦多少。
总结
邻接表和预排序遍历树的简单对比如下。
邻接表
- 优势:
- 理解简单;
- 插入速度快。
- 劣势:
- 查询路径速度较慢,需要逐级回溯。
预排序遍历树
- 优势:
- 查询路径速度快。
- 劣势:
- 需要额外字段维护路径关系;
- 插入速度较慢,当有新节点插入时,需要更新新节点的所有后续节点。
可以看出预排序遍历树相比邻接表对于树的存储方便了很多,但是二者并不能说谁优谁劣,根据不同的使用场景,邻接表也有其优势,预排序遍历树也有其劣势。
具体使用哪种实现方式,可以根据不同的业务场景去选择,如果不限于关系型数据库,也可以考虑Hierarchical Database。